For decades, “working with data” meant picking a storage engine and shaping your problem to fit it. Rows in Postgres. Documents in MongoDB. Edges in Neo4j. Parquet files in a lake. Each generation solved real problems — and each left a new silo on the org chart.
AI agents do not care about your storage taxonomy. They care about questions: Who owns this account? Can this employee see that payroll row? Which MongoDB customer maps to which CRM account? Those questions cut across systems, schemas, and naming conventions that were never designed to meet in one query.
The AI age did not make databases obsolete. It made “one more database” the wrong default answer.
1. The SQL era — tables, keys, and joins
Relational databases gave the enterprise a shared grammar: tables of rows, columns with types, primary keys that identify a row, and foreign keys that point at other rows.
Consider a minimal CRM in Postgres:
To answer “which accounts does Alex own?”, you join the tables on the foreign key:
SQL joins are elegant because they assume a single coherent schema inside one database. The optimizer knows the types. Transactions keep rows consistent. DBAs guard the boundary.
What SQL is great at
- Structured operational data with clear relationships inside one system
- ACID guarantees for finance, inventory, and identity
- Ad hoc analytics when an engineer writes the query
Where the model breaks down for AI
-
Cross-system joins do not exist. Your CRM is in Postgres; customer profiles are in
MongoDB; payroll is a CSV export. There is no
JOINacross connection strings. - Agents do not speak SQL. They speak intent — and need a governed vocabulary, not raw table names scattered in a prompt.
-
Business keys are not always keys. A MongoDB field
company: "Northwind Traders"matches Postgresaccount_nameby string equality, not by foreign key. That relationship is real — but invisible to the schema.
2. NoSQL, graph databases, and lakes — each solves a different problem
The last fifteen years added specialized stores. None of them removed silos; they optimized for different workloads.
NoSQL (e.g. MongoDB, DynamoDB)
Problem solved: flexible documents, horizontal scale, fast product iteration without
rigid migrations.
Trade-off: relationships are application-level. You denormalize, embed, or join in code.
Great for user profiles and event streams — not for federated governance across CRM + HR + finance.
Graph databases (e.g. Neo4j)
Problem solved: when the graph is the product — fraud rings, knowledge graphs,
recommendation paths native to nodes and edges.
Trade-off: you still load data into the graph. Operational Postgres and
Salesforce do not live there by default. Another copy, another sync job, another drift surface.
Data lakes & warehouses (e.g. Snowflake, S3 + Spark)
Problem solved: batch analytics, historical trends, ML feature stores, petabyte scans.
Trade-off: built for scheduled pipelines, not sub-second agent Q&A on
operational truth. Freshness is measured in hours or days. Compliance scope expands with every landing
zone.
| Store type | Optimized for | Typical AI gap |
|---|---|---|
| SQL (RDBMS) | Transactional rows, in-database joins | One system at a time; agents need cross-source joins |
| NoSQL | Flexible documents, scale-out writes | No shared schema with the rest of the stack |
| Graph DB | Native relationship traversal | Requires ingesting copies from source systems |
| Lake / warehouse | Analytics & history at scale | Stale for live agent questions; expensive to feed prompts |
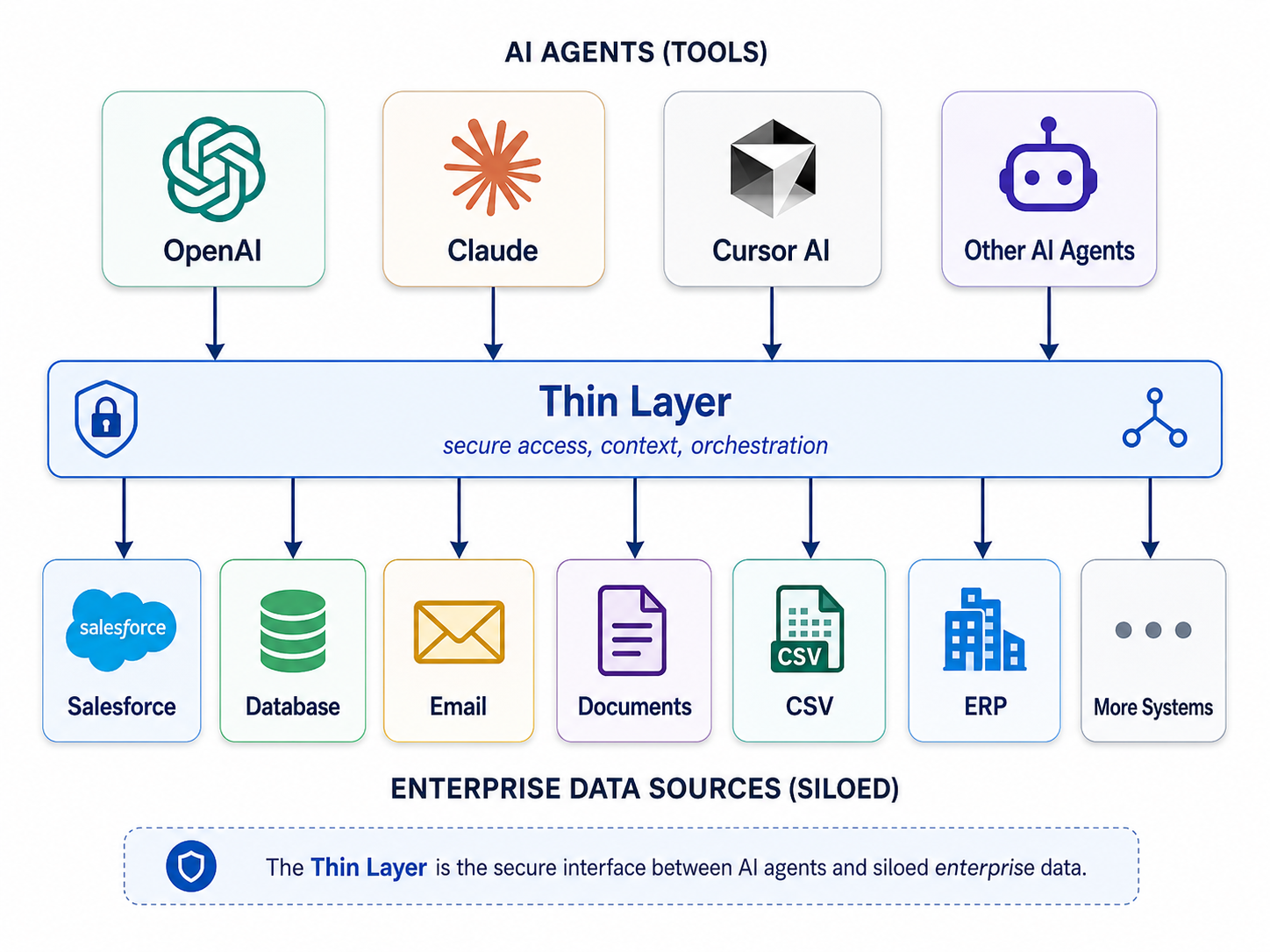
3. The AI age — a reasoning layer, not another database
When an agent asks “show me customer john’s account and who owns it,” the hard part is not storage. The rows already exist — in MongoDB and Postgres. The hard parts are:
- Meaning — map “customer”, “account”, and “owns” to the right tables and fields
- Federation — execute steps against each source without copying data
- Access — enforce who may see which rows, every time
- Proof — show which records and paths produced the answer
That is not a fifth database. It is a reasoning layer — software that sits between agents and your existing adapters, compiles intent into read-only plans, and returns answers from live systems.
AnythingGraph / Anything CLI — stores no operational data
Anything CLI is deliberately not a database in the traditional sense. It persists:
- Playbooks — business entities, relationships, and access rules (your ontology)
- Bindings — how each entity maps to Postgres tables, MongoDB collections, CSV files, Salesforce objects
- Proof envelopes — audit trails of which queries ran, not a cache of rows
Customer records stay in MongoDB. Account rows stay in Postgres. The reasoning layer does not ETL them
together — it queries in place at answer time, through MCP tools like
introspect_source, sample_source, and query_graph.
A concrete cross-source example
In a real demo playbook (crm_customer_relationship), a MongoDB customer document has
company: "Northwind Traders". Postgres has an account with the same
account_name. There is no shared UUID — only a business string.
The playbook declares:
- Entity
customer(MongoDB) linked to entitycrm_account(Postgres) - Relationship
belongs_to_accounton matching account name - Relationship
owns_accountfromcrm_usertocrm_accountinside Postgres
One agent question traverses both sources — Mongo resolve, Postgres join — with SQL and Mongo queries generated from bindings, not pasted into the prompt. See the cross-source CRM walkthrough for the full MCP session.
Database vs. reasoning layer
| Traditional database / lake | AnythingGraph reasoning layer | |
|---|---|---|
| Stores | Rows, documents, files | Playbooks, bindings, proof metadata |
| Join model | Within one engine (SQL JOIN, graph traverse) | Federated plans across adapters at query time |
| Freshness | Depends on ETL schedule or replication lag | Live reads from source systems |
| Consumer | Engineers writing queries | Agents (via MCP) asking in business terms |
| Governance | DB permissions per store | ReBAC / playbook access on every graph query |
The bottom line
We still need Postgres for transactions. We still need MongoDB for flexible documents. We still need lakes for history. None of that goes away.
What changes in the AI age is the question layer. Agents do not want another copy of your CRM — they want a governed way to reason over the copies you already have, in real time, with evidence.
That is not a new kind of disk. It is a new kind of middleware: Reasoning as Code — playbooks and bindings you version, review, and ship like any other critical infrastructure.
Stop asking which database wins. Start asking what layer lets AI use all of them safely.