The playbook we inherited
Enterprise data teams were trained on a single story: centralize first, analyze second. Pull CRM rows into a warehouse. Snapshot finance into a lake. Export documents into a search index. Chunk everything for embeddings. Paste the top fifty chunks into every agent prompt.
That story made sense when the hard problem was getting data into one place so humans could run reports. It made less sense the moment agents started asking questions every few seconds — across CRM, payroll, tickets, contracts, and APIs that were never meant to be duplicated.
Moving data was never free. In the AI age, it became the most expensive mistake on the roadmap.
What the AI age changed
1. Freshness became a product requirement
A nightly ETL job was fine for Monday’s dashboard. It is not fine when a user asks an agent at 4:47 p.m. whether a customer’s entitlement changed five minutes ago. Every copy introduces lag — and agents amplify stale answers with confident language.
2. Token economics punish “dump everything”
Re-embedding millions of rows, re-sending warehouse samples, and stuffing document corpora into context does not scale. Teams report orders-of-magnitude token burn compared with scoped queries over live systems — same question, fraction of the cost.
3. Compliance follows the copy
GDPR, HIPAA, SOC 2, and customer DPAs care about where data lives, not where your slide deck says it “should” live. Every lake, index, and vector store is a new surface to audit, breach, and explain. The agent did not create the compliance scope — your pipeline did.
4. Copies diverge from truth
Source systems change column names, retire tables, and fix bad rows continuously. A shadow copy in S3 or Pinecone drifts. The agent answers from the shadow; finance closes books from the source. That is not a hallucination — it is an architecture mismatch.
Move data vs. query in place
Move everything
ETL → lake → warehouse → embeddings → RAG → prompt. High latency to build, high cost to run, hard to prove which row authorized an answer, and painful when access rules differ by role.
Query in place
Agent asks in business terms → reasoning layer maps to live sources → governed fetch → proof bundle. Records stay in Postgres, Salesforce, MongoDB, CSV, and REST APIs where they already belong.
| Concern | Copy-first stack | Query-in-place stack |
|---|---|---|
| Freshness | Bounded by sync schedule | Answers from live systems |
| Cost | Storage + pipeline + re-embedding + tokens | Per-query fetch; scoped context |
| Access control | Often reimplemented in the index | Enforced at query time on source paths |
| Audit | “The model said so” | Source records and relationship proof |
| Time to ship | Months of integration | Playbook + bindings in days |
RAG is not a data strategy
Retrieval-augmented generation solved a narrow problem: give the model relevant text. It did not solve relationships (“who owns this account?”), row-level access (“may this AE see payroll?”), or evidence (“show me the record that justified this sentence”).
When teams treat the vector store as the new system of record, they have simply moved the data again — into chunks with fuzzy boundaries instead of tables with keys.
The thin layer that replaces the copy
The alternative is a reasoning layer between agents and siloed systems — not a new database, not another lake. Three ideas:
-
1
Playbook — what the business means Entities, relationships, and access rules in version-controlled JSON — “customer,” “owns account,” “may see payroll for records they manage.”
-
2
Bindings — where data lives One playbook, many sources: Postgres for CRM, CSV for payroll, SOQL for Salesforce — without merging them into one warehouse.
-
3
Proof — why the answer is true Every reply can carry source records and paths, so auditors and engineers replay the inference — not debate the model’s mood.
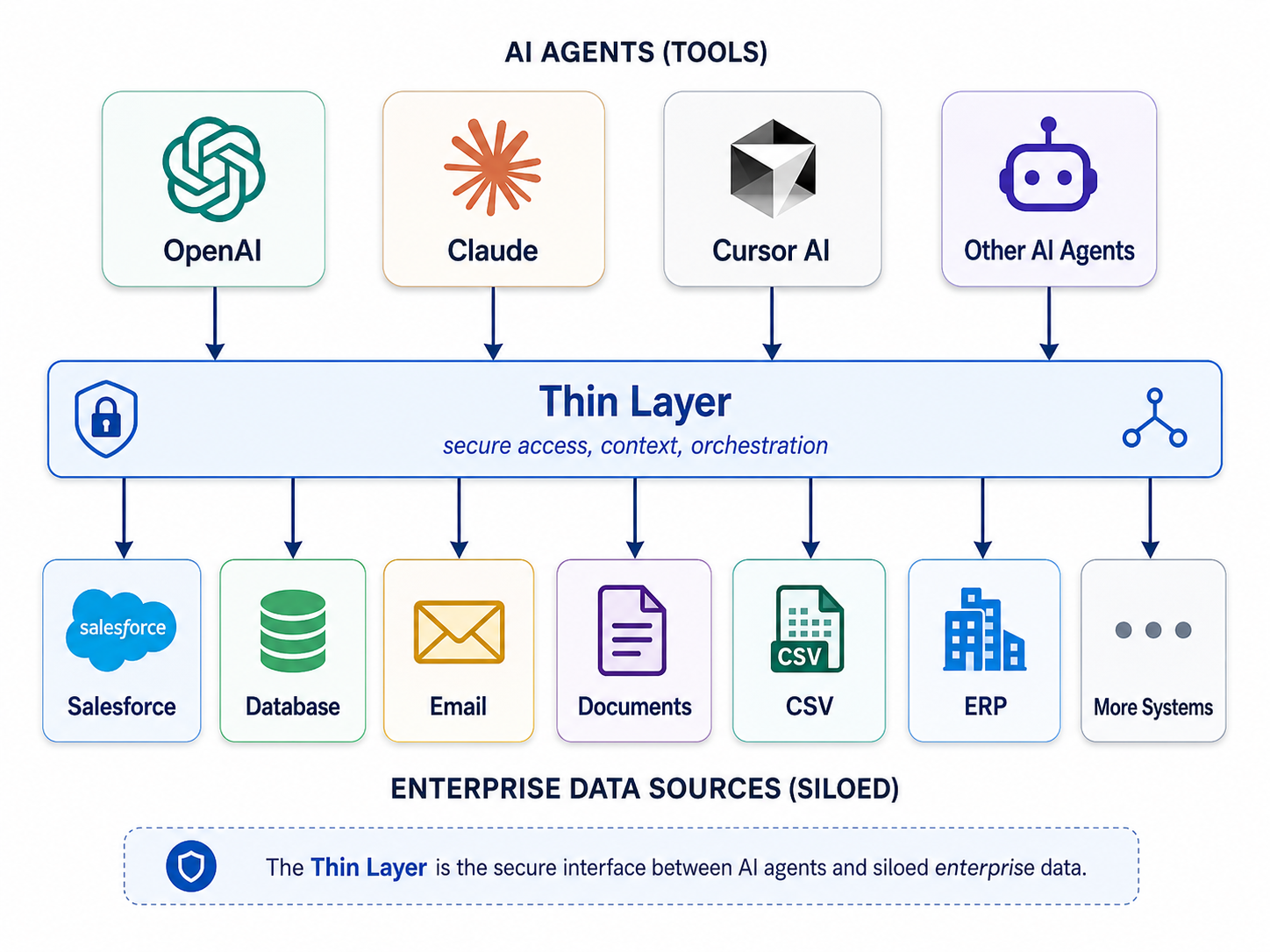
Anything CLI implements this pattern for developers today: open-source adapters for SQL, CSV, Salesforce, MySQL, SQL Server, MongoDB, and REST — connect MCP in Cursor or Claude, ask in playbook terms, get answers from live data with nothing copied into a prompt dump.
When copying still makes sense
We are not arguing against analytics warehouses or archival storage. Aggregates, historical trends, and regulated retention still belong in purpose-built systems.
The shift is narrower and more urgent: do not copy operational data into an agent context path by default. Train, batch-report, and archive where copies help. Answer agents where truth already lives.
The bottom line
The AI age did not remove data gravity. It made duplication visible — in token bills, in compliance reviews, in wrong answers that sounded right.
The teams shipping production agents are converging on the same architecture: federated query, governed vocabulary, proof on every reply. Less pipeline. Less lag. Less risk.
Stop moving data for AI. Start reasoning over it where it already is.