The paradox of the AI age
Every enterprise already has databases. Many of them. CRM in Postgres. Payroll in a CSV export. Contracts in SharePoint. Tickets in Zendesk. Finance in a warehouse that took eighteen months to build.
Then teams add more databases for AI: vector stores for embeddings, lakes for copies, indexes for search, staging tables for agent context. The instinct is understandable — if the model needs data, store more data.
But that instinct is backwards. The AI age did not create a storage shortage. It created a reasoning shortage: agents that can ask the right question, in the right vocabulary, with the right access rules, and prove what they found — without becoming another system of record.
The scarce resource is no longer disk. It is governed meaning over data that already exists.
What databases were built to store
PostgreSQL stores tuples. MongoDB stores documents. Snowflake stores columns. Pinecone stores vectors. Each generation solved a storage and retrieval problem for a particular shape of information.
That model assumes you own the bytes. You insert, update, delete. You replicate for durability. You index for speed. You backup for compliance. The database is the place truth lives.
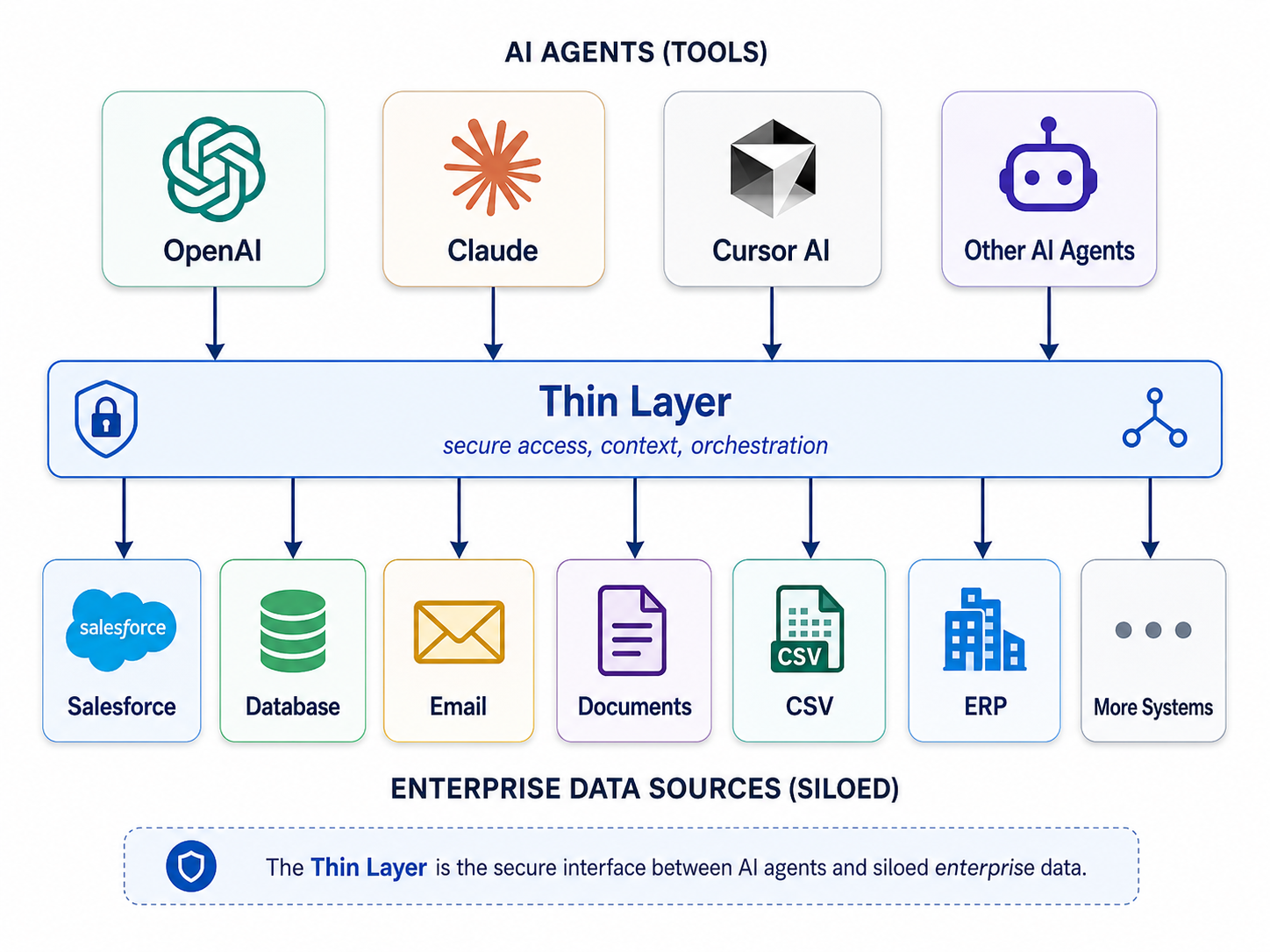
Agents break that assumption. They do not want to own payroll rows — they want to know whether Alex Anderson may see payroll for accounts she owns. They do not want a frozen copy of Salesforce — they want a live answer tied to the record that authorized it. They do not need another warehouse — they need a graph of business relationships that compiles into governed queries across systems that already exist.
AnythingGraph inverts the contract: operational data stays where it is. What gets stored, versioned, and queried like a database is the layer above — playbooks, bindings, access rules, and proof.
A database of reasoning, not rows
Call AnythingGraph a reasoning database if you need a category. It behaves like a database in the ways that matter to engineers:
- Schema — entities, fields, and relationships declared in playbooks (JSON in git)
- Queries — agents ask in business terms; the runtime compiles and executes against live sources
- Access control — ReBAC rules enforced at query time, not buried in a prompt
- Audit trail — every answer can carry proof: which source ran, which query executed, which path granted access
- Versioning — playbooks and bindings diff like code; roll forward, roll back, review in PRs
What it does not do is become the system of record for your business. Customer rows stay in Postgres. Leads stay in Salesforce. Payroll stays in the file your HR team already trusts. AnythingGraph stores the map — not the territory.
Traditional “AI database”
Copy rows → embed → index → retrieve chunks → paste into prompt. A new copy of truth, new compliance surface, new lag, new drift from source systems.
AnythingGraph
Store playbook + bindings → agent asks → governed query runs in place → proof returns with the answer. Zero operational data copied by default.
| What gets stored | Typical AI stack | AnythingGraph |
|---|---|---|
| Customer records | Copied into lake / vector DB | Left in source system (Postgres, CRM, …) |
| Business vocabulary | Scattered in prompts and docs | Playbook JSON — versioned ontology |
| Physical mapping | Hard-coded in agent tools | Bindings YAML per source |
| Who may see what | System prompt wishful thinking | ReBAC access block — enforced at runtime |
| Why the answer is true | “The model said so” | Proof envelope with source + query + path |
How a database with no data actually works
AnythingGraph sits between AI agents and the systems you already run. Three artifacts replace another warehouse:
-
1
Playbook — what the business means Entities like
crm_userandcrm_account, relationships likeowns_account, optional access rules — portable vocabulary that agents speak, not table names they guess. -
2
Bindings — where truth lives today One YAML file per source key maps playbook entities to real tables, files, or SaaS objects. Same playbook, different customer — swap bindings, not ontology.
-
3
Adapters — query in place Rust adapters for SQL, CSV, Salesforce SOQL, MongoDB, REST, and more execute at the source. Data moves only across the wire for the answer — never into a new permanent store.
A federated question — “How many accounts and payroll records does Alex Anderson have?” — compiles into scoped queries against Postgres and a CSV file. The agent gets counts and proof. Nothing lands in a AnythingGraph-owned table.
Agent → MCP → reasoning layer → playbook + bindings
↓
Postgres (CRM) CSV (payroll)
↓
answer + proof (no copy stored)
Why this matters now
1. Freshness is non-negotiable
An agent that answers from last night’s sync is wrong the moment a entitlement changes at 4:47 p.m. Query-in-place means the answer comes from the system finance and legal already trust — not a shadow copy with its own refresh schedule.
2. Compliance follows the copy
Every lake, vector index, and staging table is a new data store to audit under GDPR, HIPAA, and customer DPAs. A reasoning database adds governance without adding another place sensitive rows permanently live.
3. Token economics punish duplication
Re-embedding millions of rows and stuffing context windows does not scale. Scoped queries over live systems return only what the playbook needs — often an order of magnitude cheaper than dump-everything RAG for the same business question.
4. Relationships are not similarity
“Who owns this account?” is a graph traversal with keys and foreign columns — not a cosine distance search over chunks. Agents need structured relationships and row-level access, not another full-text index with vibes.
5. Production needs proof, not confidence
A copilot that leaks compensation to the wrong manager is an architecture failure, not a temperature problem. Storing reasoning as code — with enforced access and auditable proof — is how teams ship agents legal and security will sign off on.
This is not anti-database — it is post-copy
Warehouses, analytics marts, and archival storage still matter. Historical aggregates and regulated retention belong in purpose-built systems.
The shift is narrower and more urgent: do not treat “AI-ready” as “copy everything again.” Your operational truth already has a home. What was missing was a database-shaped layer for how agents may reason over it — vocabulary, federation, access, evidence.
Vector databases store embeddings. AnythingGraph stores meaning. That is the new primitive for the AI age.
How to run it
Anything CLI is the open-source query-in-place stack that implements this model today. Install it locally, map playbooks and bindings to your Postgres, Salesforce, CSV, and REST sources, then connect Cursor, Claude, or any MCP client — records never leave where they already live.
Playbooks are the unit of governance. MCP exposes governed tools to agents. There is no separate operational database to stand up — just reasoning artifacts in git and live queries against systems you already run.
The bottom line
We spent decades optimizing where bytes live. Agents do not need more bytes — they need a governed way to ask questions across bytes that already exist.
AnythingGraph is a new kind of database for that world: it stores playbooks, not payroll; bindings, not blobs; proof, not prompts. Your data stays home. Reasoning finally gets a home too.
In the AI age, the database that matters most is the one that stores no data at all.